
Reading TAR files in C++
This article describes a method of reading TAR archives (including .tar.gz and .tar.bz2) in C++ using Boost IOStreams.
You could use libtar for this, but the original version hasn’t been updated since 2003 and doesn’t provide you flexibility and insight to the internal structure of a TAR archive.
I highly recommend reading the english Wikipedia article and the GNU TAR format manual carefully before reading this post.
Why TAR programming sucks
From a Linux user’s point of view, TAR is great. Using TAR is ubiquitous, and it works - not only can you archive terabytes of data with a simple command, tar makes you able to select the best compression method yourself.
Programmatically accessing TAR archives however, is not that easy.
At first, TAR seems pretty straightforward. Everything is stored in constant-size 512 byte blocks, every header field has constant length, and you don’t need to save any state between different headers.
For the most basic case this actually works, but in the real world, it never works as expected. * There’s not ‘the one TAR’ specification, but there’s the ‘basic’ tar, USTAR, and vendor-specific (GNU) extensions to that * Basic TAR supports only max. 100 char filenames. GNU TAR and USTAR support extended filenames * TAR files can not only contain files and directories, but also symlinks, hardlinks, character devices, block devices, FIFOs, sparse files… * According to Wikipedia, timestamp resolution isn’t defined anywhere
Structure of a TAR entry
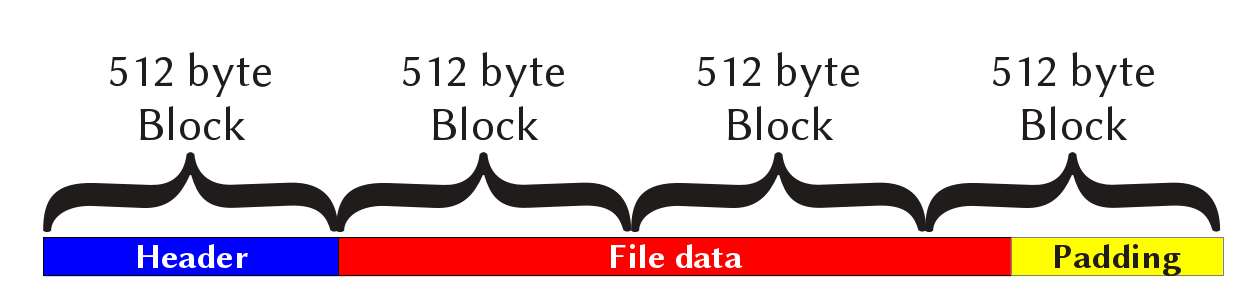
The diagram above shows the structure of a single TAR entry. The TAR file is simply a sequence of entries of this format.
The 512 byte-long file header is always written in the front of the file data - this yields an easier program structure because it makes you able to read the file sequentially without having to save information between entries. To some extent, this method is also neccessary for writing the files to magnetic or optical tapes where the data must be written sequentially.
ZIP files don’t follow this concept - they have a central directory at the end of the file. You can’t read the data sequentially, but in contrast to TARs, you can add of remove files without having to rewrite the entire archive.
The header contains a file size field that determines the length of the file. The binary file data immediately follows the header. In order to preserve the 512-byte-block structure, the last block is padded with NUL characters unless the file size is divisible by 512.
In some cases - directories, for example - the header size field is set to zero and the next block is another header.
Decoding TAR octal numbers
All numbers, especially filesizes, in the header, are encoded as octal numbers with trailing zeroes in TARs. Digits are represented as ASCII characters.
Additionally, the octal numbers may (but do not have to) contain trailing NULs.
Implementing this didnt yield correct results, I had to interpret the character directly left to the leftmost NUL (or space character) as least-significant digit in order to reproduce the file sizes yielded by tar tzvf archive.tar.gz (GNU TAR 1.26 has been used during the testing phase).
#define ASCII_TO_NUMBER(num) ((num)-48) //Converts an ascii digit to the corresponding number
/**
* Decode a TAR octal number.
* Ignores everything after the first NUL or space character.
* @param data A pointer to a size-byte-long octal-encoded
* @param size The size of the field pointer to by the data pointer
* @return
*/
static uint64_t decodeTarOctal(char* data, size_t size = 12) {
unsigned char* currentPtr = (unsigned char*) data + size;
uint64_t sum = 0;
uint64_t currentMultiplier = 1;
//Skip everything after the last NUL/space character
//In some TAR archives the size field has non-trailing NULs/spaces, so this is neccessary
unsigned char* checkPtr = currentPtr; //This is used to check where the last NUL/space char is
for (; checkPtr >= (unsigned char*) data; checkPtr--) {
if ((*checkPtr) == 0 || (*checkPtr) == ' ') {
currentPtr = checkPtr - 1;
}
}
for (; currentPtr >= (unsigned char*) data; currentPtr--) {
sum += ASCII_TO_NUMBER(*currentPtr) * currentMultiplier;
currentMultiplier *= 8;
}
return sum;
}Header data structure
While it is technically possible to support the classic tar file format, in almost any use case it’s not neccessary as the USTAR format (introducing additional header flags) is standardized for almost 25 years and pretty much any tar outside there should support it.
This page provides a the original star (a ‘flavour’ of tar) C struct for the TAR header, but in C++ we can add member functions, e.g. to decode the file size, into it. This improves the usability of the class.
struct TARFileHeader {
char filename[100]; //NUL-terminated
char mode[8];
char uid[8];
char gid[8];
char fileSize[12];
char lastModification[12];
char checksum[8];
char typeFlag; //Also called link indicator for none-UStar format
char linkedFileName[100];
//USTar-specific fields -- NUL-filled in non-USTAR version
char ustarIndicator[6]; //"ustar" -- 6th character might be NUL but results show it doesn't have to
char ustarVersion[2]; //00
char ownerUserName[32];
char ownerGroupName[32];
char deviceMajorNumber[8];
char deviceMinorNumber[8];
char filenamePrefix[155];
char padding[12]; //Nothing of interest, but relevant for checksum
/**
* @return true if and only if
*/
bool isUSTAR() {
return (memcmp("ustar", ustarIndicator, 5) == 0);
}
/**
* @return The filesize in bytes
*/
size_t getFileSize() {
return decodeTarOctal(fileSize);
}
/**
* Return true if and only if the header checksum is correct
* @return
*/
bool checkChecksum() {
//We need to set the checksum to zer
char originalChecksum[8];
memcpy(originalChecksum, checksum, 8);
memset(checksum, ' ', 8);
//Calculate the checksum -- both signed and unsigned
int64_t unsignedSum = 0;
int64_t signedSum = 0;
for (int i = 0; i < sizeof (TARFileHeader); i++) {
unsignedSum += ((unsigned char*) this)[i];
signedSum += ((signed char*) this)[i];
}
//Copy back the checksum
memcpy(checksum, originalChecksum, 8);
//Decode the original checksum
uint64_t referenceChecksum = decodeTarOctal(originalChecksum);
return (referenceChecksum == unsignedSum || referenceChecksum == signedSum);
}
};Putting the pieces together
The only thing left to do now is to process the TAR file itself.
The following program reads a TAR file, lists it contents and loads each file into memory. The file- and directory names are printed.
If you have suggestions for improvements or find a bug, please comment!
This implementation supports * GNU-specific long-filename extension * USTAR filename-prefix extension * Signed and unsigned checksum calculations (not active by default) * USTAR flag checking (not active by default) * NUL-filled block end marker (instead of EOF) * .tar.gz and .tar.bz2 plus auto-determined decompression * It uses boost::iostreams, so you could easily swap the file input for anything imaginable, e.g. a TCP stream
This implementation explicitly does not support (although it might not crash):
- Any file type except normal files and directories (including symlinks)
- Large files
- Any extensions not listed here
- Extensive unit tests (might be added some time in the future, but don’t wait for it)
- ANSI-C implementation. It might be possible, but decompression isn’t nearly as plug-and-play as with boost::iostreams.
Complete source code:
/**
* Read TAR file in C++
* Example code
*
* (C) Uli Köhler 2013
* Licensed under CC-By 3.0 Germany: http://creativecommons.org/licenses/by/3.0/de/legalcode
*
* Compile like this:
* g++ -o cpptar cpptar.cpp -lboost_iostreams -lz -lbz2
*/
#include <cstdlib>
#include <cassert>
#include <cstdio>
#include <fstream>
#include <cmath>
#include <iostream>
#include <boost/iostreams/device/file.hpp>
#include <boost/iostreams/filtering_stream.hpp>
#include <boost/iostreams/filter/gzip.hpp>
#include <boost/iostreams/filter/bzip2.hpp>
//Check file extensions
#include <boost/algorithm/string.hpp>
using namespace std;
using namespace boost::iostreams;
#define ASCII_TO_NUMBER(num) ((num)-48) //Converts an ascii digit to the corresponding number (assuming it is an ASCII digit)
/**
* Decode a TAR octal number.
* Ignores everything after the first NUL or space character.
* @param data A pointer to a size-byte-long octal-encoded
* @param size The size of the field pointer to by the data pointer
* @return
*/
static uint64_t decodeTarOctal(char* data, size_t size = 12) {
unsigned char* currentPtr = (unsigned char*) data + size;
uint64_t sum = 0;
uint64_t currentMultiplier = 1;
//Skip everything after the last NUL/space character
//In some TAR archives the size field has non-trailing NULs/spaces, so this is neccessary
unsigned char* checkPtr = currentPtr; //This is used to check where the last NUL/space char is
for (; checkPtr >= (unsigned char*) data; checkPtr--) {
if ((*checkPtr) == 0 || (*checkPtr) == ' ') {
currentPtr = checkPtr - 1;
}
}
for (; currentPtr >= (unsigned char*) data; currentPtr--) {
sum += ASCII_TO_NUMBER(*currentPtr) * currentMultiplier;
currentMultiplier *= 8;
}
return sum;
}
struct TARFileHeader {
char filename[100]; //NUL-terminated
char mode[8];
char uid[8];
char gid[8];
char fileSize[12];
char lastModification[12];
char checksum[8];
char typeFlag; //Also called link indicator for none-UStar format
char linkedFileName[100];
//USTar-specific fields -- NUL-filled in non-USTAR version
char ustarIndicator[6]; //"ustar" -- 6th character might be NUL but results show it doesn't have to
char ustarVersion[2]; //00
char ownerUserName[32];
char ownerGroupName[32];
char deviceMajorNumber[8];
char deviceMinorNumber[8];
char filenamePrefix[155];
char padding[12]; //Nothing of interest, but relevant for checksum
/**
* @return true if and only if
*/
bool isUSTAR() {
return (memcmp("ustar", ustarIndicator, 5) == 0);
}
/**
* @return The filesize in bytes
*/
size_t getFileSize() {
return decodeTarOctal(fileSize);
}
/**
* Return true if and only if the header checksum is correct
* @return
*/
bool checkChecksum() {
//We need to set the checksum to zer
char originalChecksum[8];
memcpy(originalChecksum, checksum, 8);
memset(checksum, ' ', 8);
//Calculate the checksum -- both signed and unsigned
int64_t unsignedSum = 0;
int64_t signedSum = 0;
for (int i = 0; i < sizeof (TARFileHeader); i++) {
unsignedSum += ((unsigned char*) this)[i];
signedSum += ((signed char*) this)[i];
}
//Copy back the checksum
memcpy(checksum, originalChecksum, 8);
//Decode the original checksum
uint64_t referenceChecksum = decodeTarOctal(originalChecksum);
return (referenceChecksum == unsignedSum || referenceChecksum == signedSum);
}
};
int main(int argc, char** argv) {
if (argc < 2) {
cerr << "Usage: " << argv[0] << " <TAR archive>" << endl;
return 1;
}
ifstream fin(argv[1], ios_base::in | ios_base::binary);
filtering_istream in;
//Depending on the compression format, select the correct decompressor
string filename(argv[1]);
if (boost::algorithm::iends_with(filename, ".gz")) {
in.push(gzip_decompressor());
} else if (boost::algorithm::iends_with(filename, ".bz2")) {
in.push(bzip2_decompressor());
} else if (boost::algorithm::iends_with(filename, ".tar")) {
//No decompression filter needed
} else {
cerr << "Unknown file suffix: " << filename << endl;
return 1;
}
in.push(fin);
//Initialize a zero-filled block we can compare against (zero-filled header block --> end of TAR archive)
char zeroBlock[512];
memset(zeroBlock, 0, 512);
//Start reading
bool nextEntryHasLongName = false;
while (in) { //Stop if end of file has been reached or any error occured
TARFileHeader currentFileHeader;
//Read the file header.
in.read((char*) ¤tFileHeader, 512);
//When a block with zeroes-only is found, the TAR archive ends here
if(memcmp(¤tFileHeader, zeroBlock, 512) == 0) {
cout << "Found TAR end\n";
break;
}
//Uncomment this to check all header checksums
//There seem to be TARs on the internet which include single headers that do not match the checksum even if most headers do.
//This might indicate a code error.
//assert(currentFileHeader.checkChecksum());
//Uncomment this to check for USTAR if you need USTAR features
//assert(currentFileHeader.isUSTAR());
//Convert the filename to a std::string to make handling easier
//Filenames of length 100+ need special handling
// (only USTAR supports 101+-character filenames, but in non-USTAR archives the prefix is 0 and therefore ignored)
string filename(currentFileHeader.filename, min((size_t)100, strlen(currentFileHeader.filename)));
//---Remove the next block if you don't want to support long filenames---
size_t prefixLength = strlen(currentFileHeader.filenamePrefix);
if(prefixLength > 0) { //If there is a filename prefix, add it to the string. See `man ustar`LON
filename = string(currentFileHeader.filenamePrefix, min((size_t)155, prefixLength)) + "/" + filename; //min limit: Not needed by spec, but we want to be safe
}
//Ignore directories, only handle normal files (symlinks are currently ignored completely and might cause errors)
if (currentFileHeader.typeFlag == '0' || currentFileHeader.typeFlag == 0) { //Normal file
//Handle GNU TAR long filenames -- the current block contains the filename only whilst the next block contains metadata
if(nextEntryHasLongName) {
//Set the filename from the current header
filename = string(currentFileHeader.filename);
//The next header contains the metadata, so replace the header before reading the metadata
in.read((char*) ¤tFileHeader, 512);
//Reset the long name flag
nextEntryHasLongName = false;
}
//Now the metadata in the current file header is valie -- we can read the values.
size_t size = currentFileHeader.getFileSize();
//Log that we found a file
cout << "Found file '" << filename << "' (" << size << " bytes)\n";
//Read the file into memory
// This won't work for very large files -- use streaming methods there!
char* fileData = new char[size + 1]; //+1: Place a terminal NUL to allow interpreting the file as cstring (you can remove this if unused)
in.read(fileData, size);
//-------Place code to handle the file content here---------
delete[] fileData;
//In the tar archive, entire 512-byte-blocks are used for each file
//Therefore we now have to skip the padded bytes.
size_t paddingBytes = (512 - (size % 512)) % 512; //How long the padding to 512 bytes needs to be
//Simply ignore the padding
in.ignore(paddingBytes);
//----Remove the else if and else branches if you want to handle normal files only---
} else if (currentFileHeader.typeFlag == '5') { //A directory
//Currently long directory names are not handled correctly
cout << "Found directory '" << filename << "'\n";
} else if(currentFileHeader.typeFlag == 'L') {
nextEntryHasLongName = true;
} else {
//Neither normal file nor directory (symlink etc.) -- currently ignored silently
cout << "Found unhandled TAR Entry type " << currentFileHeader.typeFlag << "\n";
}
}
//Cleanup
fin.close();
}