
How to read single value from XLS(X) using pandas
pandas can be used conveniently to read a table of values from Excel. When extracting data from real-life Excel sheets, there are often metadata fields which are not structured as a table readable by pandas.
Reading the pandas docs, it is not obvious how we can extract the value of a single cell (without any associated headers) with a fixed position, for example:
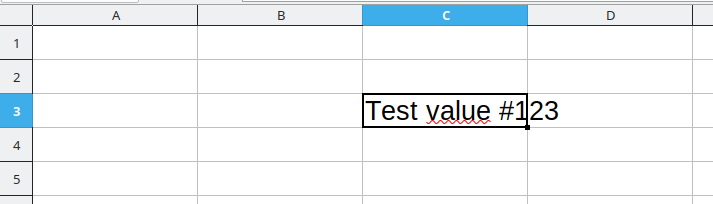
In this example, we want to extract cell C3, that is we want to end up with a string of value Test value #123. Since there is no clear table structure in this excel sheet (and other cells might contain other values we are not interested in - for example, headlines or headers), we don’t want to have a pd.DataFrame but simply a string.
This is how you can do it:
def read_value_from_excel(filename, column="C", row=3):
"""Read a single cell value from an Excel file"""
return pd.read_excel(filename, skiprows=row - 1, usecols=column, nrows=1, header=None, names=["Value"]).iloc[0]["Value"]Example usage
read_value_from_excel(“Test.xlsx”, “C”, 3) # Prints
Let’s explain the parameters we’re using as arguments to pd.read_excel():
Test.xlsx: The filename of the file you want to readskiprows=2: Row number minus one, so the desired row is the first we readusecols="C": Which columns we’re interested in - only one!nrows=1: Read only a single rowheader=None: Do not assume that the first row we read is a header rownames=["Value"]: Set the name for the single column toValue.iloc[0]: From the resultingpd.DataFrame, get the first row ([0]) by index (iloc)["Value"]From the resulting row, extract the"Value"column - which is the only column available.
In my opinion, using pandas is the best way of extracting for most real-world usecases (i.e. more focused on development speed than on execution speed) because not only does it provide automatic engine selection for .xls and .xlsx files, it’s also present on most Data Science setups anyway and provides a standardized API.