
TAR-Dateien in C++ lesen
Dieser Artikel beschreibt eine Methode zum Lesen von TAR-Archiven (inklusive .tar.gz und .tar.bz2) in C++ mit Boost IOStreams.
Man könnte dafür libtar verwenden, aber die Originalversion wurde seit 2003 nicht mehr aktualisiert und bietet weder Flexibilität noch Einblick in die interne Struktur eines TAR-Archivs.
Ich empfehle, den englischen Wikipedia-Artikel und das GNU TAR-Format-Handbuch sorgfältig zu lesen, bevor du diesen Beitrag liest.
Warum TAR-Programmierung frustrierend ist
From a Linux user’s point of view, TAR is great. Using TAR is ubiquitous, and it works - not only can you archive terabytes of data with a simple command, tar makes you able to select the best compression method yourself.
Programmatically accessing TAR archives however, is not that easy.
At first, TAR seems pretty straightforward. Everything is stored in constant-size 512 byte blocks, every header field has constant length, and you don’t need to save any state between different headers.
For the most basic case this actually works, but in the real world, it never works as expected. * There’s not ‘the one TAR’ specification, but there’s the ‘basic’ tar, USTAR, and vendor-specific (GNU) extensions to that * Basic TAR supports only max. 100 char filenames. GNU TAR and USTAR support extended filenames * TAR files can not only contain files and directories, but also symlinks, hardlinks, character devices, block devices, FIFOs, sparse files… * According to Wikipedia, timestamp resolution isn’t defined anywhere
Structure of a TAR entry
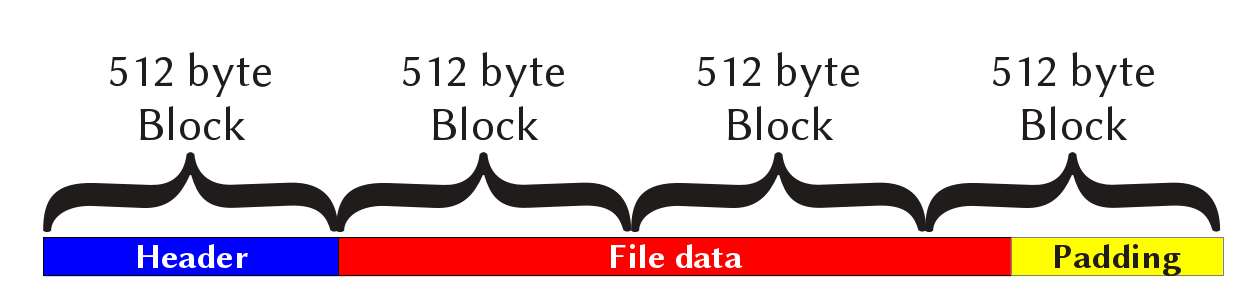
Das obige Diagramm zeigt die Struktur eines einzelnen TAR-Eintrags. Die TAR-Datei ist einfach eine Sequenz von Einträgen dieses Formats.
Der 512 Byte lange Datei-Header wird immer vor den Dateidaten geschrieben – dies ermöglicht eine einfachere Programmstruktur, da man die Datei sequenziell lesen kann, ohne Informationen zwischen Einträgen zu speichern. Bis zu einem gewissen Grad ist diese Methode auch für das Schreiben der Dateien auf magnetische oder optische Bänder notwendig, wo die Daten sequenziell geschrieben werden müssen.
ZIP-Dateien folgen diesem Konzept nicht – sie haben ein zentrales Verzeichnis am Ende der Datei. Man kann die Daten nicht sequenziell lesen, aber im Gegensatz zu TARs kann man Dateien hinzufügen oder entfernen, ohne das gesamte Archiv neu zu schreiben.
Der Header enthält ein Dateigrößenfeld, das die Länge der Datei bestimmt. Die binären Dateidaten folgen unmittelbar nach dem Header. Um die 512-Byte-Block-Struktur zu erhalten, wird der letzte Block mit NUL-Zeichen aufgefüllt, sofern die Dateigröße nicht durch 512 teilbar ist.
In einigen Fällen – z.B. bei Verzeichnissen – ist das Header-Größenfeld auf null gesetzt und der nächste Block ist ein weiterer Header.
TAR-Oktalzahlen dekodieren
Alle Zahlen, insbesondere Dateigrößen, im Header werden in TARs als Oktalzahlen mit nachfolgenden Nullen kodiert. Ziffern werden als ASCII-Zeichen dargestellt.
Zusätzlich können die Oktalzahlen (müssen aber nicht) nachfolgende NULs enthalten.
Die Implementierung ergab keine korrekten Ergebnisse; ich musste das Zeichen direkt links der am weitesten links stehenden NUL (oder Leerzeichen) als niederwertigste Ziffer interpretieren, um die Dateigrößen zu reproduzieren, die tar tzvf archive.tar.gz lieferte (GNU TAR 1.26 wurde während der Testphase verwendet).
#define ASCII_TO_NUMBER(num) ((num)-48) //Wandelt eine ASCII-Ziffer in die entsprechende Zahl um
/**
* Dekodiert eine TAR-Oktalzahl.
* Ignoriert alles nach dem ersten NUL- oder Leerzeichen.
* @param data Ein Zeiger auf eine size-Byte lange oktal-kodierte Zahl
* @param size Die Größe des Feldes, auf das der data-Zeiger zeigt
* @return
*/
static uint64_t decodeTarOctal(char* data, size_t size = 12) {
unsigned char* currentPtr = (unsigned char*) data + size;
uint64_t sum = 0;
uint64_t currentMultiplier = 1;
//Überspringe alles nach dem letzten NUL-/Leerzeichen
//In einigen TAR-Archiven hat das Größenfeld nicht-trailing NULs/Leerzeichen, daher ist dies notwendig
unsigned char* checkPtr = currentPtr; //Wird verwendet um zu prüfen, wo das letzte NUL-/Leerzeichen ist
for (; checkPtr >= (unsigned char*) data; checkPtr--) {
if ((*checkPtr) == 0 || (*checkPtr) == ' ') {
currentPtr = checkPtr - 1;
}
}
for (; currentPtr >= (unsigned char*) data; currentPtr--) {
sum += ASCII_TO_NUMBER(*currentPtr) * currentMultiplier;
currentMultiplier *= 8;
}
return sum;
}Header-Datenstruktur
Obwohl es technisch möglich ist, das klassische TAR-Dateiformat zu unterstützen, ist es in fast jedem Anwendungsfall nicht notwendig, da das USTAR-Format (das zusätzliche Header-Flags einführt) seit fast 25 Jahren standardisiert ist und so ziemlich jedes tar draußen es unterstützen sollte.
Diese Seite bietet die originale star (eine „Variante" von tar) C-Struktur für den TAR-Header, aber in C++ können wir Member-Funktionen hinzufügen, z.B. um die Dateigröße zu dekodieren. Dies verbessert die Verwendbarkeit der Klasse.
struct TARFileHeader {
char filename[100]; //NUL-terminiert
char mode[8];
char uid[8];
char gid[8];
char fileSize[12];
char lastModification[12];
char checksum[8];
char typeFlag; //Auch Link-Indikator genannt für Nicht-UStar-Format
char linkedFileName[100];
//USTar-spezifische Felder -- NUL-gefüllt in Nicht-USTAR-Version
char ustarIndicator[6]; //"ustar" -- 6. Zeichen könnte NUL sein, aber Ergebnisse zeigen, dass es nicht muss
char ustarVersion[2]; //00
char ownerUserName[32];
char ownerGroupName[32];
char deviceMajorNumber[8];
char deviceMinorNumber[8];
char filenamePrefix[155];
char padding[12]; //Nichts von Interesse, aber relevant für die Prüfsumme
/**
* @return true wenn und nur wenn
*/
bool isUSTAR() {
return (memcmp("ustar", ustarIndicator, 5) == 0);
}
/**
* @return Die Dateigröße in Bytes
*/
size_t getFileSize() {
return decodeTarOctal(fileSize);
}
/**
* Gibt true zurück wenn und nur wenn die Header-Prüfsumme korrekt ist
* @return
*/
bool checkChecksum() {
//Wir müssen die Prüfsumme auf null setzen
char originalChecksum[8];
memcpy(originalChecksum, checksum, 8);
memset(checksum, ' ', 8);
//Prüfsumme berechnen -- sowohl signed als auch unsigned
int64_t unsignedSum = 0;
int64_t signedSum = 0;
for (int i = 0; i < sizeof (TARFileHeader); i++) {
unsignedSum += ((unsigned char*) this)[i];
signedSum += ((signed char*) this)[i];
}
//Prüfsumme zurückkopieren
memcpy(checksum, originalChecksum, 8);
//Original-Prüfsumme dekodieren
uint64_t referenceChecksum = decodeTarOctal(originalChecksum);
return (referenceChecksum == unsignedSum || referenceChecksum == signedSum);
}
};Die Teile zusammenfügen
Das Einzige, was noch zu tun ist, ist die TAR-Datei selbst zu verarbeiten.
Das folgende Programm liest eine TAR-Datei, listet ihren Inhalt und lädt jede Datei in den Speicher. Die Datei- und Verzeichnisnamen werden ausgegeben.
Wenn du Verbesserungsvorschläge hast oder einen Fehler findest, bitte kommentieren!
Diese Implementierung unterstützt * GNU-spezifische Long-Filename-Erweiterung * USTAR-Filename-Prefix-Erweiterung * Signed- und Unsigned-Prüfsummenberechnung (standardmäßig nicht aktiv) * USTAR-Flag-Prüfung (standardmäßig nicht aktiv) * NUL-gefüllten Block-End-Marker (statt EOF) * .tar.gz und .tar.bz2 plus automatisch bestimmte Dekompression * Sie verwendet boost::iostreams, sodass man die Dateieingabe leicht gegen alles Denkbare austauschen könnte, z.B. einen TCP-Stream
Diese Implementierung unterstützt nicht (obwohl sie möglicherweise nicht abstürzt):
- Dateitypen außer normalen Dateien und Verzeichnissen (inklusive Symlinks)
- Große Dateien
- Erweiterungen, die hier nicht aufgelistet sind
- Umfangreiche Unit-Tests (könnten in Zukunft hinzugefügt werden, aber warte nicht darauf)
- ANSI-C-Implementierung. Es mag möglich sein, aber Dekompression ist bei weitem nicht so Plug-and-Play wie mit boost::iostreams.
Vollständiger Quellcode:
/**
* TAR-Datei in C++ lesen
* Beispielcode
*
* (C) Uli Köhler 2013
* Lizenziert unter CC-By 3.0 Germany: http://creativecommons.org/licenses/by/3.0/de/legalcode
*
* Kompilieren wie folgt:
* g++ -o cpptar cpptar.cpp -lboost_iostreams -lz -lbz2
*/
#include <cstdlib>
#include <cassert>
#include <cstdio>
#include <fstream>
#include <cmath>
#include <iostream>
#include <boost/iostreams/device/file.hpp>
#include <boost/iostreams/filtering_stream.hpp>
#include <boost/iostreams/filter/gzip.hpp>
#include <boost/iostreams/filter/bzip2.hpp>
//Dateierweiterungen prüfen
#include <boost/algorithm/string.hpp>
using namespace std;
using namespace boost::iostreams;
#define ASCII_TO_NUMBER(num) ((num)-48) //Wandelt eine ASCII-Ziffer in die entsprechende Zahl um (vorausgesetzt es ist eine ASCII-Ziffer)
/**
* Dekodiert eine TAR-Oktalzahl.
* Ignoriert alles nach dem ersten NUL- oder Leerzeichen.
* @param data Ein Zeiger auf eine size-Byte lange oktal-kodierte Zahl
* @param size Die Größe des Feldes, auf das der data-Zeiger zeigt
* @return
*/
static uint64_t decodeTarOctal(char* data, size_t size = 12) {
unsigned char* currentPtr = (unsigned char*) data + size;
uint64_t sum = 0;
uint64_t currentMultiplier = 1;
//Überspringe alles nach dem letzten NUL-/Leerzeichen
//In einigen TAR-Archiven hat das Größenfeld nicht-trailing NULs/Leerzeichen, daher ist dies notwendig
unsigned char* checkPtr = currentPtr; //Wird verwendet um zu prüfen, wo das letzte NUL-/Leerzeichen ist
for (; checkPtr >= (unsigned char*) data; checkPtr--) {
if ((*checkPtr) == 0 || (*checkPtr) == ' ') {
currentPtr = checkPtr - 1;
}
}
for (; currentPtr >= (unsigned char*) data; currentPtr--) {
sum += ASCII_TO_NUMBER(*currentPtr) * currentMultiplier;
currentMultiplier *= 8;
}
return sum;
}
struct TARFileHeader {
char filename[100]; //NUL-terminiert
char mode[8];
char uid[8];
char gid[8];
char fileSize[12];
char lastModification[12];
char checksum[8];
char typeFlag; //Auch Link-Indikator genannt für Nicht-UStar-Format
char linkedFileName[100];
//USTar-spezifische Felder -- NUL-gefüllt in Nicht-USTAR-Version
char ustarIndicator[6]; //"ustar" -- 6. Zeichen könnte NUL sein, aber Ergebnisse zeigen, dass es nicht muss
char ustarVersion[2]; //00
char ownerUserName[32];
char ownerGroupName[32];
char deviceMajorNumber[8];
char deviceMinorNumber[8];
char filenamePrefix[155];
char padding[12]; //Nichts von Interesse, aber relevant für die Prüfsumme
/**
* @return true wenn und nur wenn
*/
bool isUSTAR() {
return (memcmp("ustar", ustarIndicator, 5) == 0);
}
/**
* @return Die Dateigröße in Bytes
*/
size_t getFileSize() {
return decodeTarOctal(fileSize);
}
/**
* Gibt true zurück wenn und nur wenn die Header-Prüfsumme korrekt ist
* @return
*/
bool checkChecksum() {
//Wir müssen die Prüfsumme auf null setzen
char originalChecksum[8];
memcpy(originalChecksum, checksum, 8);
memset(checksum, ' ', 8);
//Prüfsumme berechnen -- sowohl signed als auch unsigned
int64_t unsignedSum = 0;
int64_t signedSum = 0;
for (int i = 0; i < sizeof (TARFileHeader); i++) {
unsignedSum += ((unsigned char*) this)[i];
signedSum += ((signed char*) this)[i];
}
//Prüfsumme zurückkopieren
memcpy(checksum, originalChecksum, 8);
//Original-Prüfsumme dekodieren
uint64_t referenceChecksum = decodeTarOctal(originalChecksum);
return (referenceChecksum == unsignedSum || referenceChecksum == signedSum);
}
};
int main(int argc, char** argv) {
if (argc < 2) {
cerr << "Verwendung: " << argv[0] << " <TAR-Archiv>" << endl;
return 1;
}
ifstream fin(argv[1], ios_base::in | ios_base::binary);
filtering_istream in;
//Abhängig vom Kompressionsformat den korrekten Dekompressor auswählen
string filename(argv[1]);
if (boost::algorithm::iends_with(filename, ".gz")) {
in.push(gzip_decompressor());
} else if (boost::algorithm::iends_with(filename, ".bz2")) {
in.push(bzip2_decompressor());
} else if (boost::algorithm::iends_with(filename, ".tar")) {
//Kein Dekompressionsfilter nötig
} else {
cerr << "Unbekannte Dateierweiterung: " << filename << endl;
return 1;
}
in.push(fin);
//Initialisiere einen NUL-gefüllten Block zum Vergleichen (NUL-gefüllter Header-Block --> Ende des TAR-Archivs)
char zeroBlock[512];
memset(zeroBlock, 0, 512);
//Beginne mit dem Lesen
bool nextEntryHasLongName = false;
while (in) { //Abbrechen wenn Dateiende erreicht wurde oder ein Fehler auftrat
TARFileHeader currentFileHeader;
//Datei-Header lesen.
in.read((char*) ¤tFileHeader, 512);
//Wenn ein Block nur aus Nullen gefunden wird, endet das TAR-Archiv hier
if(memcmp(¤tFileHeader, zeroBlock, 512) == 0) {
cout << "TAR-Ende gefunden\n";
break;
}
//Auskommentieren um alle Header-Prüfsummen zu prüfen
//Es scheint TARs im Internet zu geben, die einzelne Header enthalten, die nicht zur Prüfsumme passen, obwohl die meisten Header passen.
//Das könnte auf einen Codefehler hindeuten.
//assert(currentFileHeader.checkChecksum());
//Auskommentieren um auf USTAR zu prüfen, falls du USTAR-Features benötigst
//assert(currentFileHeader.isUSTAR());
//Dateinamen in einen std::string umwandeln für einfachere Handhabung
//Dateinamen mit Länge 100+ benötigen spezielle Behandlung
// (nur USTAR unterstützt Dateinamen mit 101+ Zeichen, aber in Nicht-USTAR-Archiven ist das Präfix 0 und wird daher ignoriert)
string filename(currentFileHeader.filename, min((size_t)100, strlen(currentFileHeader.filename)));
//---Entferne den nächsten Block, wenn du keine langen Dateinamen unterstützen möchtest---
size_t prefixLength = strlen(currentFileHeader.filenamePrefix);
if(prefixLength > 0) { //Wenn es ein Dateinamen-Präfix gibt, füge es zum String hinzu. Siehe `man ustar`LON
filename = string(currentFileHeader.filenamePrefix, min((size_t)155, prefixLength)) + "/" + filename; //min limit: Not needed by spec, but we want to be safe
}
//Verzeichnisse ignorieren, nur normale Dateien verarbeiten (Symlinks werden derzeit komplett ignoriert und können Fehler verursachen)
if (currentFileHeader.typeFlag == '0' || currentFileHeader.typeFlag == 0) { //Normale Datei
//GNU TAR lange Dateinamen behandeln -- der aktuelle Block enthält nur den Dateinamen, während der nächste Block Metadaten enthält
if(nextEntryHasLongName) {
//Dateiname aus dem aktuellen Header setzen
filename = string(currentFileHeader.filename);
//Der nächste Header enthält die Metadaten, also ersetze den Header vor dem Lesen der Metadaten
in.read((char*) ¤tFileHeader, 512);
//Long-Name-Flag zurücksetzen
nextEntryHasLongName = false;
}
//Jetzt sind die Metadaten im aktuellen Datei-Header gültig -- wir können die Werte lesen.
size_t size = currentFileHeader.getFileSize();
//Protokollieren, dass wir eine Datei gefunden haben
cout << "Datei gefunden '" << filename << "' (" << size << " Bytes)\n";
//Datei in den Speicher lesen
// Dies funktioniert nicht für sehr große Dateien -- dort Streaming-Methoden verwenden!
char* fileData = new char[size + 1]; //+1: Ein terminales NUL platzieren, um die Datei als C-String zu interpretieren (kann entfernt werden, falls ungenutzt)
in.read(fileData, size);
//-------Hier Code zum Verarbeiten des Dateiinhalts platzieren---------
delete[] fileData;
//Im TAR-Archiv werden gesamte 512-Byte-Blöcke für jede Datei verwendet
//Daher müssen wir jetzt die aufgefüllten Bytes überspringen.
size_t paddingBytes = (512 - (size % 512)) % 512; //Wie lang die Auffüllung auf 512 Bytes sein muss
//Auffüllung einfach ignorieren
in.ignore(paddingBytes);
//----Entferne die else if und else Zweige, wenn du nur normale Dateien verarbeiten möchtest---
} else if (currentFileHeader.typeFlag == '5') { //Ein Verzeichnis
//Aktuell werden lange Verzeichnisnamen nicht korrekt behandelt
cout << "Verzeichnis gefunden '" << filename << "'\n";
} else if(currentFileHeader.typeFlag == 'L') {
nextEntryHasLongName = true;
} else {
//Weder normale Datei noch Verzeichnis (Symlink etc.) -- derzeit still ignoriert
cout << "Unbehandelten TAR-Eintrags-Typ " << currentFileHeader.typeFlag << " gefunden\n";
}
}
//Aufräumen
fin.close();
}